
CS 336 课程笔记,仅供参考。
Overview
basic
构建一个完整的语言模型由三步组成:tokenization,模型结构和训练方法
Tokenization
tokenizer 可以实现字符串和 int 序列(tokens)之间的转换
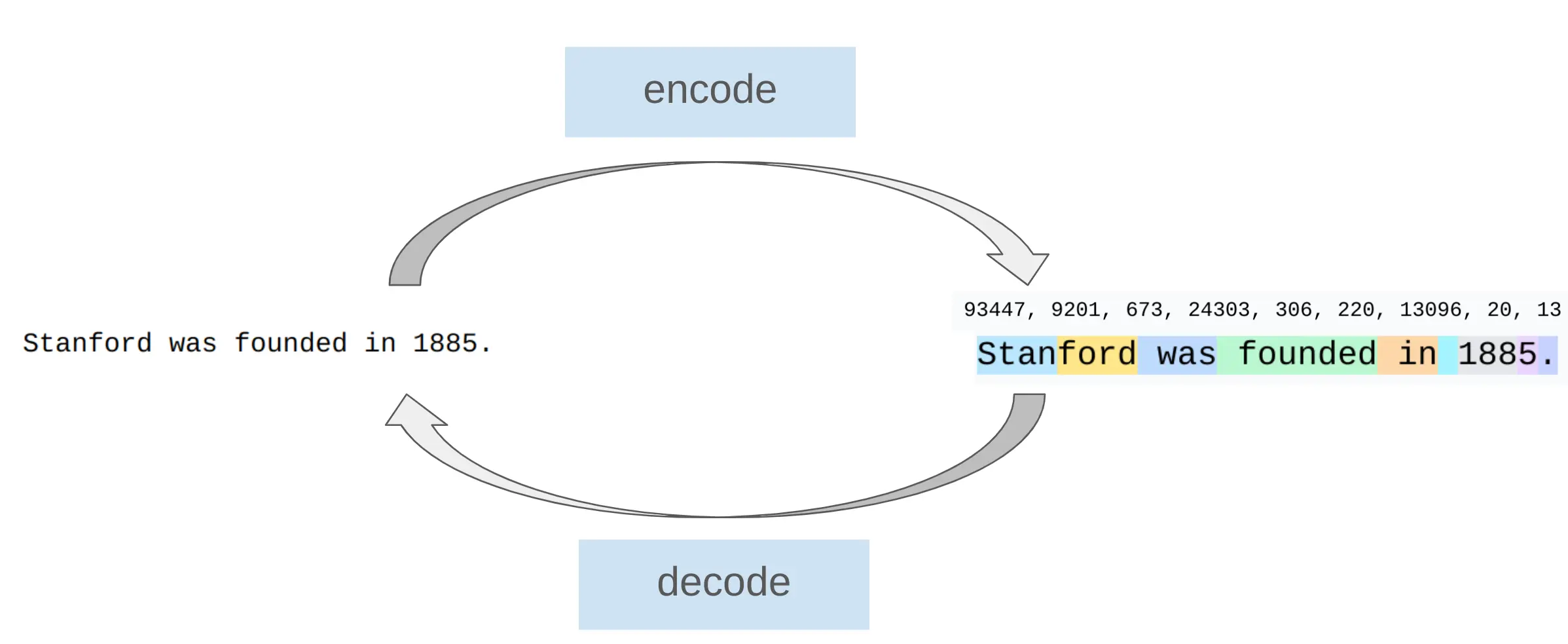
tokenizer
本课程主要讲解的是 Byte-Pair Encoding(BPE)tokenizer Sennrich+ 2015
此外还有一个无需 tokenizer 的方法,但是目前并没有起到显著成效 Xue+ 2021, Yu+ 2023, Pagnoni+ 2024, Deiseroth+ 2024
结构
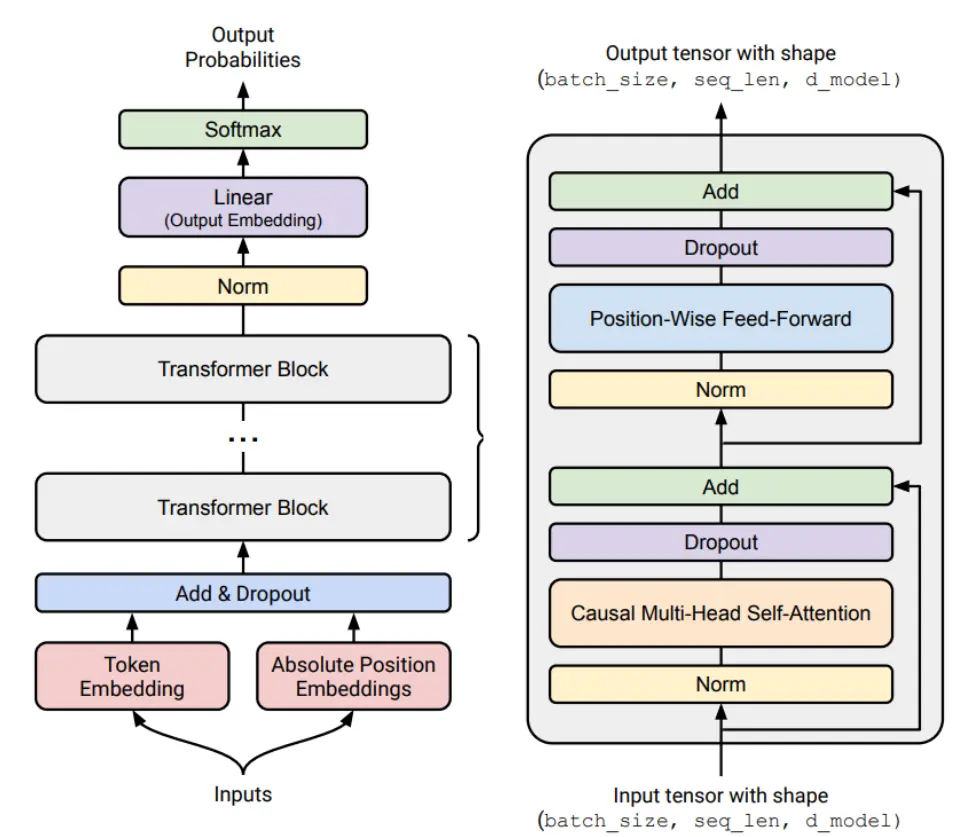
transformer architecture
在 transformer 基础上又有一些变种:
- 损失函数:ReLU,SwiGLU Shazeer 2020
- 位置编码:sinusoidal,RoPE Su+ 2021
- 归一化:LayerNorm,RMSNorm Zhang+ 2019
- 归一化层的位置:pre-norm vs post-norm Xiong+ 2020
- MLP 层:混合专家模式 Shazeer+ 2017
- 注意力:滑动窗,线性注意力 Jiang+ 2023, Katharopoulos+ 2020
- 低维注意力:GQA,MLA Ainslie+ 2023, DeepSeek-AI+ 2024
- State-space models: Hyena Poli+ 2023
训练方法
- 优化器:AdamW,Muon,SOAP Kingma+ 2014, Loshchilov+ 2017, Keller 2024, Vyas+ 2024
- 学习率缩放:cosine,WSD Loshchilov+ 2016, Hu+ 2024
- Batch size:critical batch size McCandlish+ 2018
- 正则化:dropout,weight decay
- 超参数:head number,hidden dimension
系统
Kernels
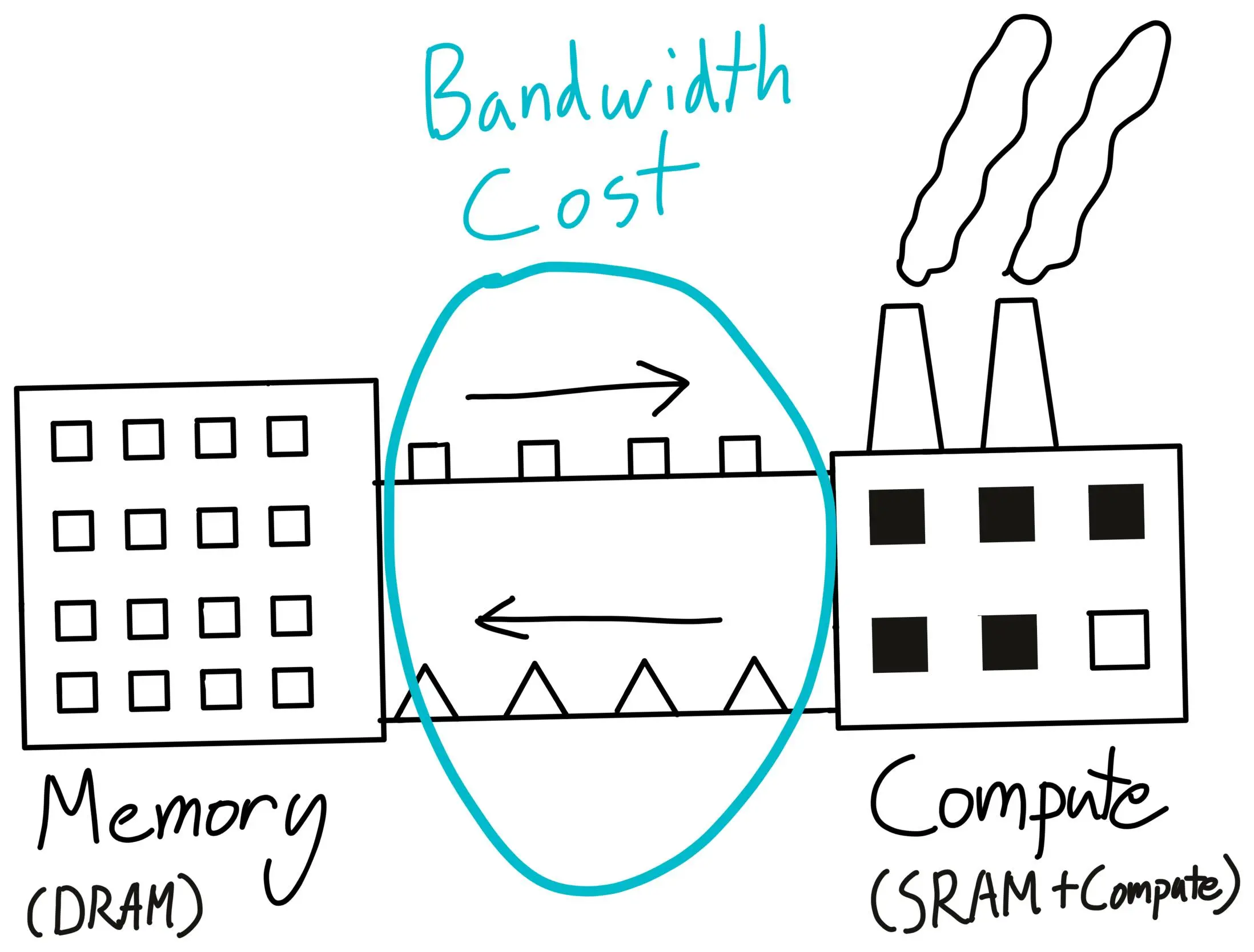
dram and sram
在 GPU 内部,DRAM 和 SRAM 之间进行数据传输,需要最大化数据传输的能效
Parallelism
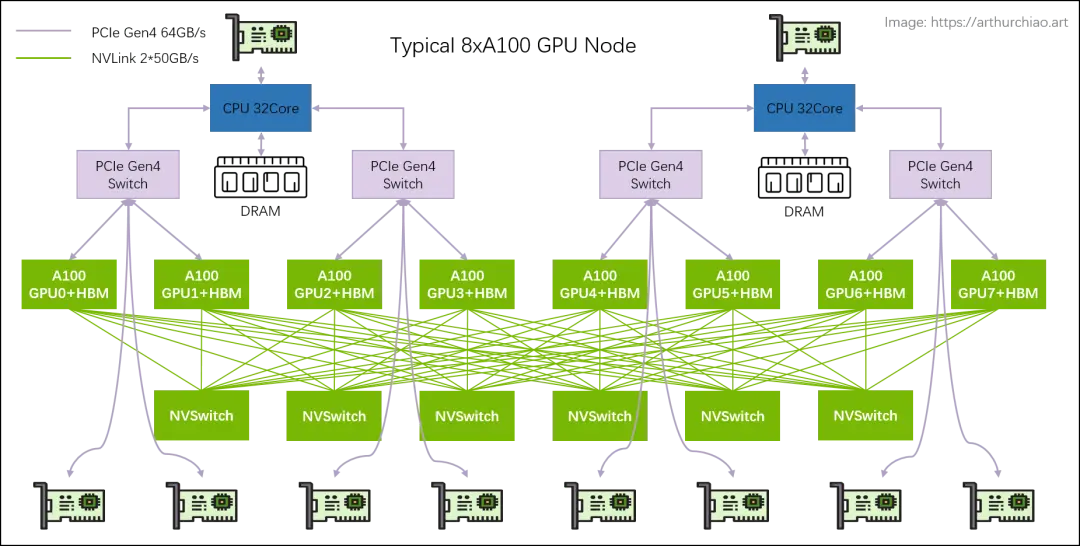
gpu group
如果有一个 GPU 集群,数据在 GPU 之间的移动将会比 GPU 内部更为低效
- 进行 collective operation:gather,reduce,all-reduce
- GPU 数据分片(参数,激活状态,梯度,优化器状态)
- 分布计算:数据、tensor、pipeline、sequence 并行
推理
一般来说,推理计算比训练计算需求更高
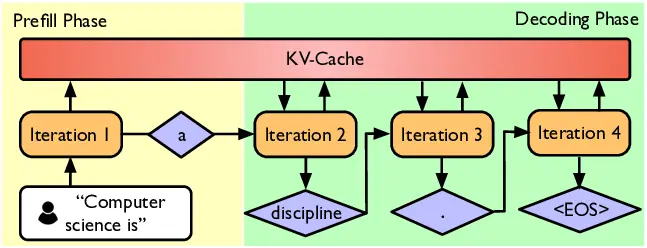
inference phase
推理可以分为 prefill 和 decode 两个阶段
- prefill:给定 token,可以同时处理所有token
- decode:需要递归依次生成token
提高 decode 效率的方法:
- 使用更加轻量的模型(模型剪枝、量化、蒸馏)
- speculative decoding:使用轻量模型初步生成一些 token,然后再通过全量模型打分
- 系统优化:KV cache,batch 化
Scaling Laws
进行小规模的实验,来预测大规模场景下的超参数和损失
给定一定的 FLOPs 资源,训练一个更大的模型更好,还是使用更多的 token 训练更好
Compute-optimal scaling laws: Kaplan+ 2020, Hoffmann+ 2022
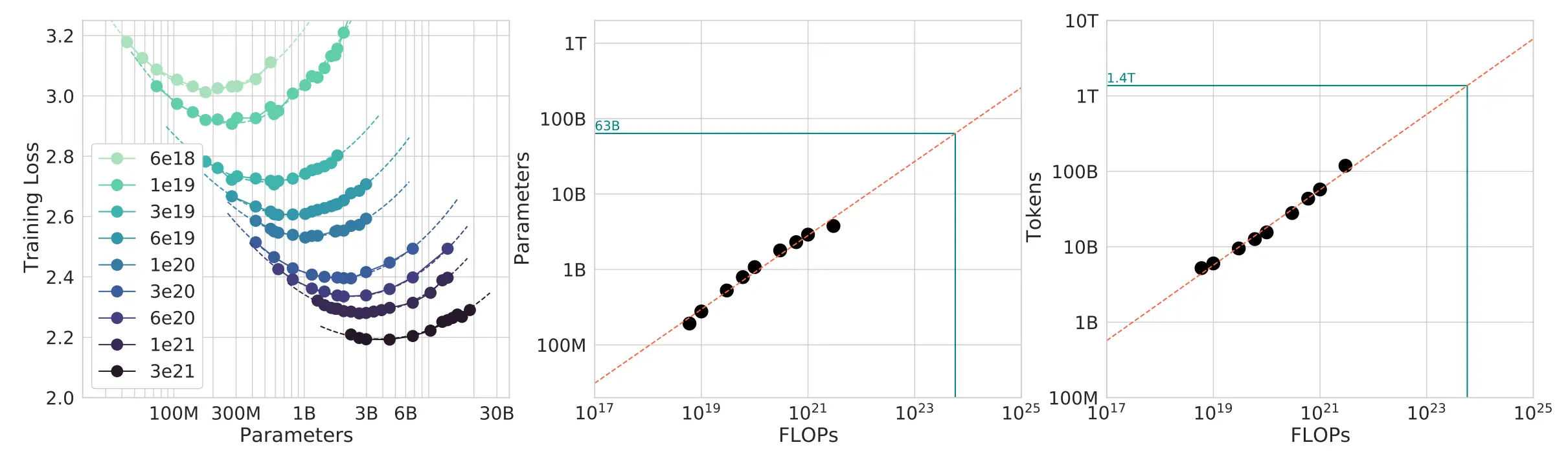
scaling law
Data
我们希望模型具有什么样的能力:多语言、编程、数学
模型评估
- 困惑度 perplexity:大模型评估的基础方式
- 标准测试:M M L U,HellaSwag,GSM8K
- 指令跟随:ALpacaEval,IFEval,WildBench
- LM-as-a-judge
- 全系统评估:RAG,agent
数据筛选
- 数据来源:互联网上爬虫得到的网页,数据,arXiv 论文,Github 代码等
- 可能需要数据授权
- 格式:HTML,PDF,文件夹
数据处理
- 格式转换:将 HTML/PDF 转换成文本
- 过滤:过滤掉有害内容
- 去重:降低计算量,防止模型 memorization
对齐
经过预训练后,模型已经非常擅长预测下一个 token,但是需要通过对齐让模型真正可用
- 让语言模型可以遵守对指令做出响应的范式
- 优化响应风格
- 防止产生有害内容
对齐可以分为两个阶段:监督学习微调和反馈强化学习
监督学习微调 SFT
使用指令数据 instruction data <prompt, response> 对进行监督学习训练
| |
Preference Data
经过指令数据的有监督训练,我们已经有了一个初步的可以跟随指令的模型,我们可以通过使用 preference data 训练让模型更加强大,而不需要更多的指令标注数据
preference data:让多个模型对同一个 prompt 给出响应,用户给出偏好
| |
- Proximal Policy Optimization (PPO) from reinforcement learning Schulman+ 2017 Ouyang+ 2022
- Direct Policy Optimization (DPO): for preference data, simpler Rafailov+ 2023
- Group Relative Preference Optimization (GRPO): remove value function Shao+ 2024
Tokenization
一个 tokenizer 需要实现编码和解码的功能:
- 编码:将字符串编码成 token(int 类型的索引)
- 解码:将 token 转换回字符串
其中所有可能的 token 的个数称为 vocabulary size
Character-based tokenization
一个字符串由一序列字符组成,每个字符可以直接被转换成整数索引值作为 token。例如,直接使用 ord 可以得到字符的 ASCII 码,可以作为一个简单的tokenizer
缺点:
- Unicode 字符的数量大概是 150K,导致 vocabulary size 非常大
- 很多字符在句子中很少使用,造成了稀疏性,vocabulary 非常低效
Byte-based tokenization
Unicode 字符串也可以直接用一系列的 byte 表示,这些 byte 可以使用 0 到 255 的整数索引
| |
只用 255 种 byte 就可以表示所有的字符窗,vocabulary size 是 255。但是一个 byte 对应了一个整数 token,压缩率为 1, tokenization 之后得到的 token 序列非常长,造成自注意力计算量非常大
Word-based tokenization
NLP 模型中常用的是基于单词的 tokenization,首先将一个句子划分成单词序列,然后将每个可以划分的单词指定一个整数索引,就可以建立一个tokenizer
| |
缺点:
- 单词的总数非常大
- 很多单词使用率非常低,模型很难充分学习
- 很难确定一个固定大小的词典,存在没有见过的词
Byte Pair Encoding
首先将字符串表示成 byte,然后让 tokenizer 自动选择 byte 组成单词(不一定是完整的人类单词),那么一些常见的单词将可以使用一个 token 表示,对于少见或者没有见过的单词可以使用多个 token 组合表示
| |